
Mêmes causes, mêmes effets ? La campagne de vaccination contre la Covid-19, lancée fin décembre 2020, démarre dans une certaine confusion. Notamment concernant les données de son suivi. Jusqu’à ce mardi 12 janvier, aucune donnée publique à l’échelle nationale ou locale n’était disponible. Il fallait se satisfaire de quelques articles de presse ou de communiqués des autorités publiques ou agences régionales de santé (ARS).
Beaucoup de données sur la Covid mais ça n’a pas toujours été le cas
Des difficultés dans le traitement et la libération des données qui rappellent celles du suivi de l’épidémie depuis bientôt un an. Aujourd’hui, et depuis plusieurs mois maintenant, via un tableau de bord dédié, le portail data.gouv.fr ou encore Geodes, (le portail de données de santé publique cartographiées de Santé Publique France) de nombreuses données de suivi de l’épidémie sont disponibles. Avec un rythme de mise à jour quotidien ou hebdomadaire selon les indicateurs. Mais cela n’a pas toujours été le cas. Et l’entreprise de transparence, vantée notamment par le président de la République, est encore imparfaite, certaines données n’étant toujours pas disponibles (voir plus bas).
Depuis que nous utilisons, comme d’autres, les données mises à disposition par l’organisme Santé Publique France, via notamment son espace sur le portail data.gouv.fr, nous avons parfois râlé face à l’absence de diffusion de certaines données. Des données absentes qui guidaient en partie l’action publique. L’idée avait alors germé de faire ce retour que vous lisez actuellement. Depuis, certaines données manquantes ont été libérées mais il nous semblait encore utile de revenir dessus.
Couvre-feu dans les métropoles, mais où étaient passées les données ?
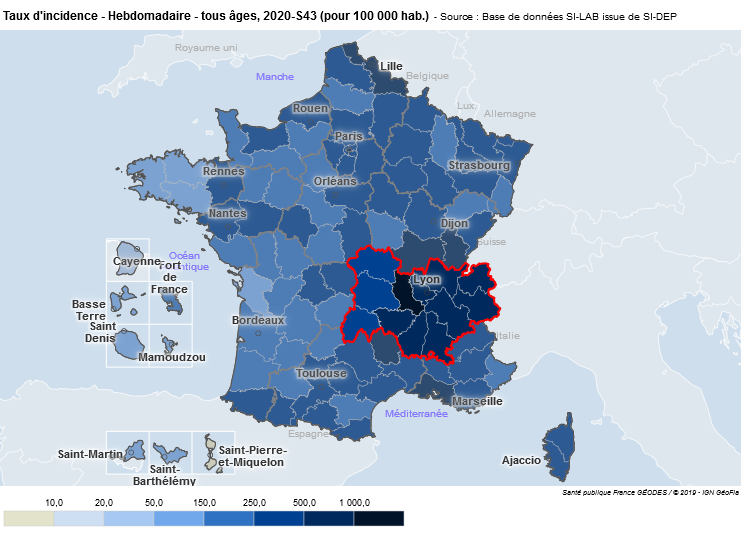
C’est le cas notamment du taux d’incidence à l’échelle infra-départementale (à l’échelle des métropoles ou des communes par exemple).
Rappelez-vous à l’automne dernier, avant que n’arrive « la deuxième vague », des premiers couvre-feu territorialisés ont été mis en place. Ils ont été effectifs à partir du 17 octobre dans les métropoles de Lyon, Saint-Étienne et Grenoble. Ils étaient notamment décidés sur la base d’une évolution inquiétante du taux d’incidence (nombre de cas pour 100 000 habitants), à l’échelle des métropoles.
Or, ces données ont seulement été disponibles publiquement à partir du 15 octobre seulement. Pourtant, ces données sont consolidées depuis le 20 septembre (au moins) selon les fichiers mis à disposition. Jusque là, certains chiffres étaient donnés lors de points presse notamment.
Bref, les chiffres existaient mais n’étaient pas libérés publiquement.
Taux d’incidence par communes : toujours aucune donnée précise
Même chose pour les données à l’échelle des communes. Rappelez-vous là aussi l’automne dernier. Les préfets comme celui du Rhône, déterminaient chaque semaine les communes où le port du masque devenait obligatoire dans l’espace public. Ils se basaient là aussi notamment sur le taux d’incidence à l’échelle communale et appuyaient chacune de leurs décisions par les chiffres transmis notamment par l’Agence régionale de santé (ARS). L’occasion alors de découvrir ces chiffres à cette échelle qui n’existaient pas dans les fichiers libérés sur les plateformes habituelles.
Ces données sont d’ailleurs intéressantes. Le taux d’incidence de l’épidémie est ainsi consultable à l’échelle des communes sur une carte du portail Geodes de Santé Publique France (et uniquement à cet endroit, sauf erreur de notre part). Toutefois, aucune donnée précise n’est donnée par commune car l’indicateur est découpé par tranches. Impossible de connaître donc le taux d’incidence précis d’une commune pour une semaine donnée. Santé Publique France a justifié ainsi :
« Les taux exacts ne sont pas affichés afin d’éviter l’identification des personnes testées, notamment celles qui ont un test positif. »
Cet indicateur est un ratio, en aucun cas une donnée brute. Comment alors parvenir à identifier des personnes ? Mystère.
Des tranches de 10 ans mais des données pour les plus de 65 ans
Autre élément curieux : la ventilation par tranches d’âge. Dans la communication et les décisions en matière sanitaires, il est très souvent fait référence aux « plus de 65 ans ». Vous trouverez alors par exemple des cartes sur le portail Geodes concernant des indicateurs de l’épidémie de Covid-19 renseignés pour les plus de 65 ans. Ce qui sous-entend que la ventilation des données est opérée par tranches de 5 ans au moins.
Or, dans tous les jeux de données mis à disposition par ailleurs (sur le portail data.gouv.fr notamment), la ventilation se fait par tranche de 10 ans (vous pouvez le voir dans toutes nos visualisations). Pourquoi ne pas libérer les données qui semblent exister à une échelle plus fine ? Mystère.
Comment questionner quand on ne dispose pas des données ?
Cela fait peut-être chipoteur. Toutefois, il est parfaitement malaisant (pour le moins) en tant que journaliste mais aussi en tant que citoyen, de lire, entendre ou voir certaines décisions se baser sur des données qui ne sont pas divulguées et mises à disposition alors même qu’un effort de transparence total est annoncé. Difficile aussi de questionner plus précisément ces mêmes décisions quand on n’en dispose pas.
L’arrivée tardive, au compte-goutte ou l’absence de certaines, laissent le sentiment désagréable pour les observateurs que nous sommes que posséder la donnée est une forme de pouvoir. Ces retards s’expliquent certainement en grande partie par la complexité de l’organisation et la rapidité demandée pour la publication de ces données. Mais face à un dispositif déployé en partie sous une forme de pression populaire, chaque retard peut être perçu comme une volonté de retenir ou de ne pas diffuser une donnée.
Un trop plein plutôt qu’un manque de données sur la Covid-19 ?
Malgré tout, les jeux de données présents sur les portails évoqués plus haut sont nombreux. Paradoxalement, la libération des données de suivi de l’épidémie de Covid-19 souffrirait plutôt d’un trop plein que de manques.
Les intitulés parfois nébuleux, malgré des notices explicatives, ne favorisent pas une lecture et une compréhension rapides. Ils sont également éparpillés. Ainsi, pour réaliser nos points de suivi hebdomadaire régional et notre page de visualisations de certains indicateurs par département, nous récupérons des données à trois endroits différents : sur les espaces de Santé Publique France et du ministère de la santé sur data.gouv.fr et sur le portail Geodes. D’autres sont consultables sur le tableau de bord d’Etalab mais on ne retrouve pas toujours les jeux de données réutilisables sur les autres portails, ou alors ils ne sont pas à jour.
Si son existence reste à saluer, cette entreprise de libération de la donnée n’aurait pas pu être lancée aussi vite sans une forme de pression publique (légitime) de citoyens, experts ou journalistes. Une mise en place qui a engendré une autre pression, forte, sur les équipes techniques chargées de son déploiement. Un contexte qui explique sûrement en partie les imperfections actuelles des remontées de données.
Covid-19, bon ou mauvais cas d’école en matière d’open data ?
Il nous semble toutefois que cette situation dénote un manque de culture de l’« open data » (accès et usage libre de données numériques, ndlr) au sein de certaines administrations malgré des efforts entrepris depuis quelques années. Une lacune que le récent rapport du député Eric Bothorel (LREM) « Pour une politique publique de la donnée » pointe d’ailleurs, parfois de façon cinglante. Il regrette notamment l’absence de communication et transmission de données parfois à l’intérieur d’une même administration.
Un exemple dans cette crise : la gestion des cas contacts. L’Assurance Maladie, censée assurer le traçage des cas contacts, n’avait pas la possibilité de croiser sa base de données avec celle des résultats des tests de dépistage, Sidep, afin de s’assurer que les cas contacts aient été dépistées. Le caractère sensible des données et de l’absence d’un cadre juridique permettant ce travail est avancé pour expliquer l’impossibilité de faire ce travail.
Le député classe en revanche du côté des points positifs le dispositif de remontée et de libération des données de suivi de l’épidémie du Sars-Cov-2 et de la maladie Covid-19. Reconnaissons à ce dispositif le mérite d’exister et d’avoir été déployé en un temps très court malgré la difficulté de la tâche. Sa mise en place montre aussi et surtout, nous semble-t-il, tout ce qu’il faudrait améliorer. Des initiatives citoyennes deviennent ainsi plus largement utilisées ou plébiscitées, parfois même par les spécialistes du sujet, comme celles de CovidTracker ou celle de Germain Forestier.
Ce dispositif de libération des données sur la Covid-19 est donc à la fois un motif d’espoir et la preuve d’un manque de culture et d’organisation actuellement en matière d’open data au sein de l’administration.
Faire infuser l’open data
Dans un prolongement à ces lignes, nous reviendrons sur l’utilisation que nous faisons de ces données. Nous verrons et pointerons leurs limites, leur caractère parfois incomplet voire pour certaines leur fiabilité. Autant de raisons supplémentaires, à nos yeux, de poursuivre cette logique de l’open data.
Cette culture doit aussi infuser chez certains intermédiaires comme les journalistes pour ensemble améliorer la compréhension d’une situation à travers les données disponibles.

Rue89Lyon est menacé ! Enquêter sur l’extrême droite, mettre notre nez dans les affaires de patrons peu scrupuleux, être une vigie des pouvoirs politiques… Depuis 14 ans, nous assurons toutes ces missions d’utilité publique pour la vie locale. Mais nos finances sont fragiles. Nous avons besoin de 30 000 euros au 16 avril pour continuer d’être ce contre-pouvoir local l’année prochaine.
En 2025, nous faisons face à trois menaces :
- Un procès-bâillon : nous allons passer au tribunal face à Jean-Michel Aulas, ex-patron de l’OL qui nous attaque en diffamation.
- Des réseaux sociaux hostiles : Facebook, X, mais aussi Google, ces plateformes invisibilisent de plus en plus les médias indépendants en ligne.
- La montée de l’extrême droite : notre travail d’enquête sur le sujet nous expose et demande des moyens. Face à Vincent Bolloré ou Pierre-Edouard Stérin qui rachètent des médias pour pousser leur idéologie mortifère, notre média indépendant est un espace de résistance.
Pour toutes ces raisons, nous avons besoin de votre soutien : abonnez-vous ou faites un don à Rue89Lyon !


Chargement des commentaires…