




L’intelligence artificielle (IA) a le vent en poupe. Et les débats qu’elle agite sont pour le moins houleux ! Pas une semaine ne passe sans qu’elle ne défraie la chronique. Alors que ses partisans y voient un moyen de simplifier nos quotidiens, de guérir des maladies incurables ou de trouver de nouveaux débouchés économiques, ses contempteurs dénoncent le risque de destruction d’emplois, d’abêtissement de nos sociétés, et même de destruction du lien social. Tantôt louée pour ses vertus, tantôt dénoncée pour ses prétentions démiurgiques, l’IA inquiète autant qu’elle suscite la curiosité.
Les données, le nerf de la guerre
Et la curiosité de l’IA s’oriente essentiellement vers la nôtre puisqu’elle se nourrit de nos usages, comportements et pratiques… En un mot de nos données. Mais ces données portent bien mal leur nom, tant elles se vendent à prix d’or !
Il est important de s’arrêter quelque peu sur les termes. En fait l’intelligence artificielle, qu’on appelle aujourd’hui générative (pensons à Chat GPT), est un programme informatique complexe qui a été entraîné sur des volumes colossaux de données. Ce sont des textes, des conversations, des images qui sont collectés et digérés par la machine, et dont elle est intrinsèquement dépendante pour son fonctionnement. Ils lui donnent la capacité d’anticiper avec une grande probabilité des suites de mots logiques ou d’associer des mots entre eux ou avec des images.

Ces nouvelles machines impressionnent souvent par leur puissance de calcul. Elle s’incarne dans des termes tels que le deep-learning, le machine-learning et les réseaux neuronaux. Mais leur véritable valeur, passée et à venir, réside dans leur capacité à ingérer d’immenses banques de données pour enrichir leur apprentissage et créer des applications spécifiques.
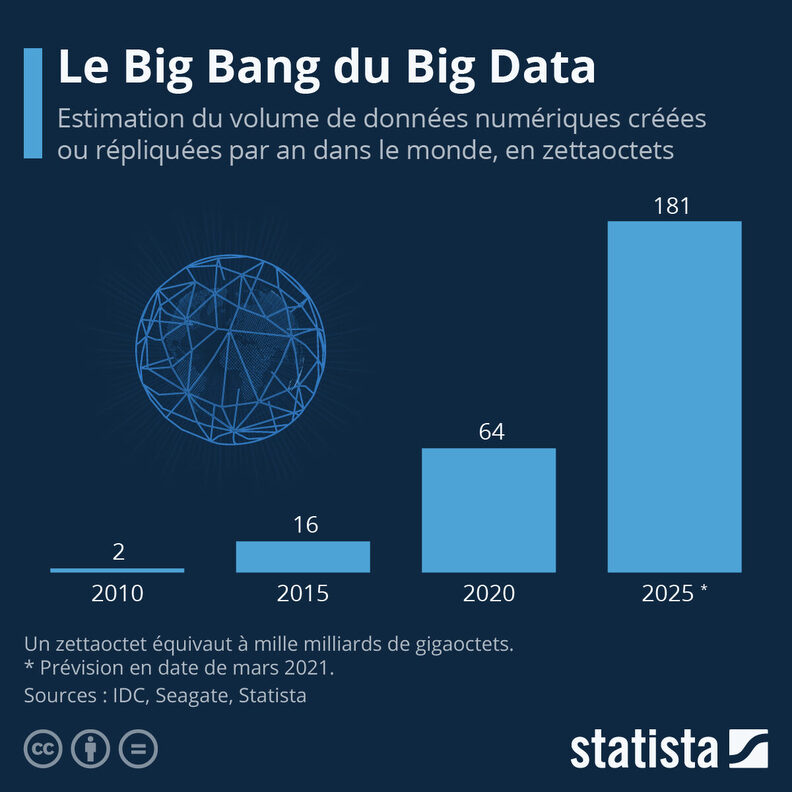
Or comme toute mécanique, l’IA repose sur une dimension matérielle. Son pétrole, c’est la donnée ; et celle-ci pourrait se tarir. D’après un article du Wall Street Journal, les entreprises spécialisées dans l’IA pourraient bientôt se heurter à un problème majeur : l’intégralité des données d’Internet ne suffirait plus. Pour pallier ce manque de nouvelles données, dorénavant insuffisantes en quantité, certains explorent la possibilité d’utiliser du contenu généré synthétiquement, c’est-à-dire déjà traité par d’autres IA.
Ceci pourrait mener à un phénomène appelé « model collapse », et faire courir le risque d’un effondrement des modèles linguistiques. Il s’agit d’une sorte de consanguinité numérique, un cercle vicieux où les IA s’entraîneraient sur des contenus produits par d’autres IA et perdraient en qualité.
Des données qui ne flottent pas dans l’air
Au-delà du risque de pénurie, il convient aussi de lever les yeux vers les nuages. Penchons nous un instant sur ce fameux cloud qui stocke nos données. En fait, les données ne flottent pas dans l’air ! Le numérique nécessite un ancrage physique et son fonctionnement a des conséquences pour l’environnement qu’il ne faut pas sous-estimer.
Il est constitué d’ordinateurs, d’écrans, de smartphones, mais aussi de millions de kilomètres de câbles en cuivre et de fibres optiques, de milliers de data centers, de milliards de chargeurs de téléphones, etc. Rien qu’en 2019, on recensait près de 34 milliards d’équipements pour 4,1 milliards d’utilisateurs, soit 8 équipements par utilisateur. Et pensons quelque peu au poids de ces données dites immatérielles… En 2019, la masse de cet univers numérique atteignait près 223 millions de tonnes, soit l’équivalent de 5 fois celle du parc automobile français !
Et si le bon usage des données contribue à une optimisation de certains systèmes, celle-ci s’accompagne bien souvent d’un effet rebond. En fait, le progrès apporté par la technologie est souvent annihilé par le changement de comportement qu’il induit et l’on comprend ainsi mieux les préoccupations énergétiques liées au boom du secteur du numérique à venir. Si le numérique était un État, il aurait environ 2 à 3 fois l’empreinte carbone de la France, selon une étude de Green IT publiée en 2019.


En parlant d’État, le secteur public s’est vite engouffré dans la voie du tout numérique. Gage de simplification, les halls de nos services publics sont remplacés par des « guichets numériques » et autres « portails d’accès ».
Les villes s’ouvrent à l’open data, autorisant de ce fait des réemplois via des API – des interfaces de programmation – censées assurer une meilleure qualité de vie aux habitants et habitantes. De la publication des données de mobilité pour développer une mobilité dite « servicielle » au compteur Linky, en passant par les flottes de vélos en libre-service ou le ramassage d’ordure… la donnée est un objet utile.
Riche d’appropriations infinies, elle vise à réaliser la promesse de la smart-city : une ville efficace, efficiente, pilotable en temps réel et à distance. S’il convient de se réjouir de certaines avancées salutaires permises par l’usage de la data, il s’agit aussi de ne pas être naïf. Aujourd’hui, cette ambition de connexion se projette aussi jusqu’à l’intérieur de nos foyers, qui vend le bonheur dans un frigo relié en 6G à notre futur Iphone !
Mais à qui profitent les algorithmes ?
L’usage des données et des algorithmes n’a rien d’un sujet technique. Il s’agit en réalité d’une question éminemment politique. Celle de notre capacité à faire commun, de notre propension à se soustraire d’une rationalité purement instrumentale et probabiliste. Car celle-ci comporte des risques qui menace l’action publique.
Loin d’être des outils neutres, les intelligences artificielles épousent les biais de leurs concepteurs. Pire, les données et algorithmes qui permettent d’entraîner les intelligences artificielles ne sont pas sans conséquences. Bien souvent, elles participent à la perpétuation d’un certain nombre de discriminations qui reproduisent des formes d’inégalités déjà existantes.
En 2022, le maire de Madrid José Luis Almeida a ainsi commandé une étude visant à brosser un panorama de la vulnérabilité de la capitale espagnole. Réalisée par la firme internationale Accenture à l’aide d’un algorithme nommé IGUALA, l’enquête a ainsi mis au jour des résultats pour le moins étonnants. Radicalement opposés aux précédentes études portées par les sociologues de l’Université Carlos III, les résultats dessinent une nouvelle géographie de la vulnérabilité.
Le problème tient en fait au choix des paramètres. Car les indicateurs statistiques traditionnels tels que le taux de chômage, de pauvreté, le degré d’infrastructures de transport sont minorés. En fait, la vulnérabilité y est définie à partir du strict champ de compétence municipale (cadre de vie, tranquillité publique…). Au total, c’est un quartier riche du centre de Madrid, Ibiza, qui est identifié par l’algorithme comme le plus vulnérable. Et cette supercherie a des conséquences financières très concrètes, puisque ces résultats orientent les investissements publics.
En France, le cas récent de la CAF a lui aussi révélé les risques de discrimination induits par le numérique. Fin 2023, l’association La Quadrature du Net, des journalistes du Monde et de Lighthouse Reports ont montré que l’algorithme utilisé par la CAF pour prioriser les contrôles ciblait davantage les populations les plus vulnérables.
Selon l’enquête, l’algorithme CRISTAL aurait été mis en œuvre de manière opaque, sans transparence quant à ses critères de fonctionnement ou à ses implications pour les bénéficiaires de prestations. De plus, il générerait des résultats biaisés, entraînant des suspensions injustes ou erronées de prestations pour de nombreux bénéficiaires. Sous couvert de scientificité, les algorithmes invisibilisent en fait des décisions toutes politiques. Par manque de transparence, ils construisent une prétendue objectivité qui demeure toute factice, puisqu’on ne peut voir sous le capot de leur machinerie.
Donner un sens aux données
La technologie n’est jamais bonne ou mauvaise en soi. Véritable pharmakon, du terme grec, qui signifie à la fois remède et poison, c’est l’usage qu’on en fait qui en détermine sa valeur. Réfléchir aux questions de la data et des algorithmes est une priorité.
Car cette architecture numérique façonne maintenant les formes urbaines, les formes de vie entre humains et non humains. Faire l’économie de la donnée, c’est risquer de se voir voler nos vies. Sa réappropriation, sa politisation c’est peut-être le projet de constituer un monde en commun. De la Smart city aux smart citizens, il n’y a qu’un pas.
Et c’est là l’ambition de cette nouvelle journée de discussion sur les ondes de Radio Anthropocène !


Rue89Lyon est menacé ! Enquêter sur l’extrême droite, mettre notre nez dans les affaires de patrons peu scrupuleux, être une vigie des pouvoirs politiques… Depuis 14 ans, nous assurons toutes ces missions d’utilité publique pour la vie locale. Mais nos finances sont fragiles. Nous avons besoin de 30 000 euros au 16 avril pour continuer d’être ce contre-pouvoir local l’année prochaine.
En 2025, nous faisons face à trois menaces :
- Un procès-bâillon : nous allons passer au tribunal face à Jean-Michel Aulas, ex-patron de l’OL qui nous attaque en diffamation.
- Des réseaux sociaux hostiles : Facebook, X, mais aussi Google, ces plateformes invisibilisent de plus en plus les médias indépendants en ligne.
- La montée de l’extrême droite : notre travail d’enquête sur le sujet nous expose et demande des moyens. Face à Vincent Bolloré ou Pierre-Edouard Stérin qui rachètent des médias pour pousser leur idéologie mortifère, notre média indépendant est un espace de résistance.
Pour toutes ces raisons, nous avons besoin de votre soutien : abonnez-vous ou faites un don à Rue89Lyon !

Chargement des commentaires…